Redis vs. HPKV: 100M keys over network

Why another Redis vs. HPKV article?
It's been less than 3 months since we officially released HPKV and we've been working on a lot of new features and improvements. We've received a lot of questions about how HPKV compares to other KV stores and how it performs in different scenarios. Redis being the most popular KV store and the fact that it's a great choice for many use cases, it naturally is the first thing anyone would compare HPKV to.
Back in February, just before we officially went out of beta, we published a blog post on Redis vs. HPKV where we compared the performance of Redis and HPKV on a single node locally. This was a great way to show the performance of HPKV and how it compares to Redis; however, we wanted to show how this translates to an over-the-network scenario as well as talk about a few details that caused a number of questions and confusion. So here we are.
Why should you care?
Performance is not about the numbers, it's about the context. In other words, what is the performance-to-cost ratio? How much does it cost to get that performance? How much does it cost to maintain that performance? How much does it cost to scale that performance?
Given enough scale, shaving microseconds can save you a lot of money. In other words, you can translate microseconds to dollars. More on that later.
The setup
The setup is simple: we have 2 nodes, one is used as a server and the other is used as a client. Both machines are located in the EU and the same region, but not in the same datacenter; however, the latency between the two machines is less than 1ms.
Machine A (Server):
- Intel Core i9-13900
- 128 GB DDR5 ECC RAM
- SAMSUNG PM9A3 1.92 TB NVMe SSD
- Ubuntu 24.04 LTS - 6.8.0-60-generic
Machine B (Client):
- Intel Core i5-12500
- 128 GB DDR4 ECC RAM
- SAMSUNG 980 PRO 512 GB NVMe SSD
- Ubuntu 24.04 LTS - 6.8.0-60-generic
Network:
- 1 Gbps Ethernet
Software:
- Redis 7.0.15
- HPKV 1.17
Methodology & Considerations
- Although we used the same machine for both HPKV and Redis, we ensured that only one of the two is running at a time.
- No other application/service was running on the machines, only the OS and the KV store.
- We followed the best practices mentioned in the Redis Benchmarking Guide for Redis testing.
- For HPKV we used the RIOC benchmarking tool, which was configured to match the Redis benchmark parameters. HPKV also provides a local vectored call interface which can bring the single operation latency close to the 300ns range for GET, but since Redis is operating as a server and to keep the comparison fair, we used RIOC for this benchmark. You can find the code for the benchmarking tool here.
- HPKV provides both in-memory and disk persistence. For disk persistence comparison, we used Redis with AOF enabled; however, there are some fundamental differences between the two that we will discuss later.
Understanding HPKV local performance
Before we dive into the over-the-network comparison benchmark, we need to understand how HPKV performs locally. This local benchmarking using HPKV's local vectored call interface is a great way to understand HPKV's strengths and the careful design choices we made to achieve them.
HPKV is highly optimized for local performance. It's designed to be a high-performance, low-latency, low-cost KV store. It uses a combination of techniques to achieve this, including:
- Advanced lock-free design for highly concurrent read operations
- Fine-grained locking for highly concurrent write operations
- Custom memory allocator for low-latency memory allocation
- CPU cache-friendly design
- Custom file system for low-latency disk access
- Fast hybrid memory-disk architecture for low-memory environments
- And more...
One of the key differences between HPKV and Redis is that Redis is only a server and the only way to communicate with it is through the network. HPKV is a local-first KV store and it's RIOC that provides a network interface to communicate with it. This design choice allows HPKV to achieve low-latency and high-performance for applications that are running on the same machine, but make no mistake,HPKV is no slouch when it comes to over-the-network performance.
If you'd like to learn more about RIOC, we have a blog post that explains it in detail here.
Without further ado, let's dive into the benchmarks.
Local Benchmark Tool
The local benchmark tool is a simple, single-threaded tool that writes, reads and deletes a number of unique keys, each exactly once. This eliminates the data skew and the effect of the cache.
400M keys, single thread, local benchmark
The following shows the result of a 400M 25-byte keys, 25-byte values, single-thread benchmark. HPKV is running in memory-only mode with hash buckets set to 2^28.
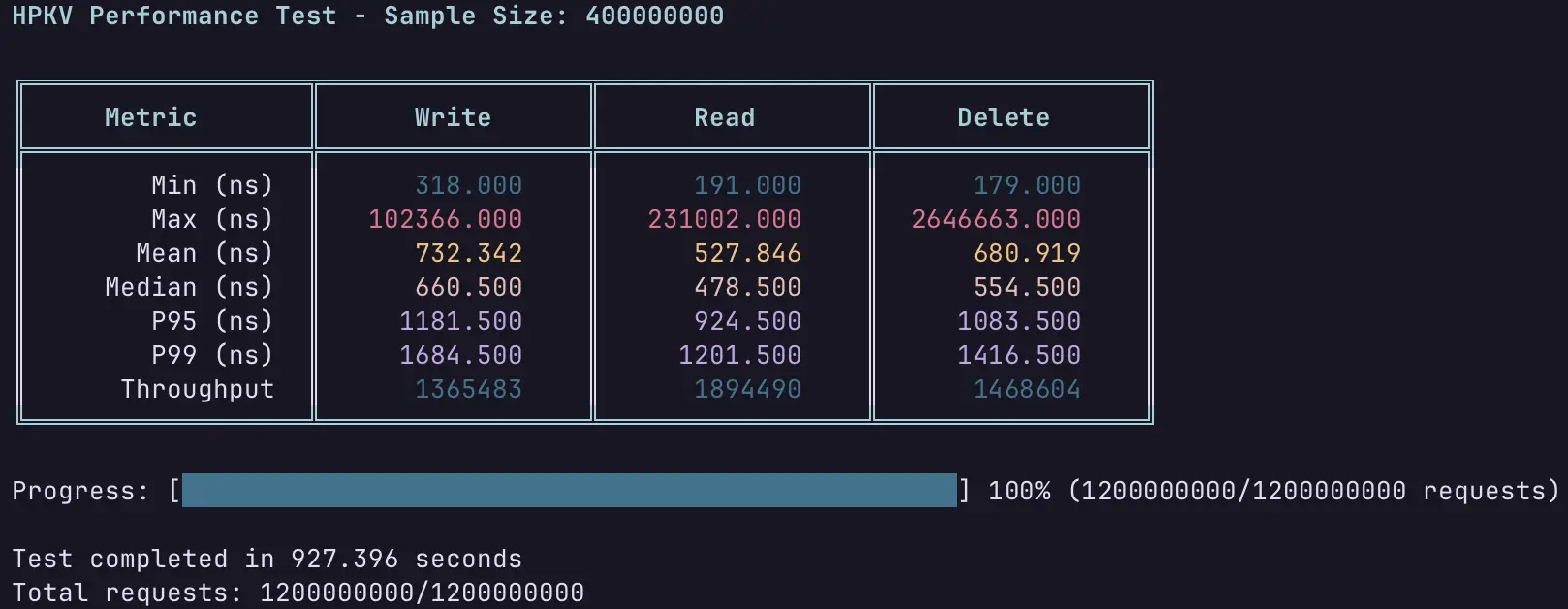
As you can see, HPKV is fast! The read performance is quite stable with the number of keys growing beyond 1 billion on a single node, due to its careful hash table design, and the other operations (INSERT, DELETE, RANGE, ATOMIC_INC/DEC, etc.) scale logarithmically with the number of keys, even in hybrid disk mode.
Please note that the 0.500 at the end of the P50, P95 and P99 latency values is an artifact of the histogram binning in the test program.
100M keys, single thread, hybrid memory-disk, local benchmark
The hybrid memory-disk mode in HPKV implements an asynchronous write-behind buffering system with durability characteristics similar to Redis AOF in everysec mode. Upon each write request, HPKV immediately updates in-memory data structures and enqueues a write buffer entry to per-CPU buffers. Background worker threads asynchronously process these entries, performing batched disk writes with immediate synchronization. This architecture provides strong consistency guarantees through memory-resident data while ensuring eventual persistence through lock-free, work-queue-based disk operations.
After a successful write to the disk, the value of the KV pair is removed from memory to keep the memory footprint low. Upon a read request, the value is read from the disk and cached in memory with an LRU eviction policy, memory pressure detection and intelligent prefetching.
With this mechanism, HPKV can operate on machines with very low memory. For example, you can easily run HPKV on a t4g.nano instance with 1GB of memory!
Now the same test as above but in hybrid memory-disk mode.
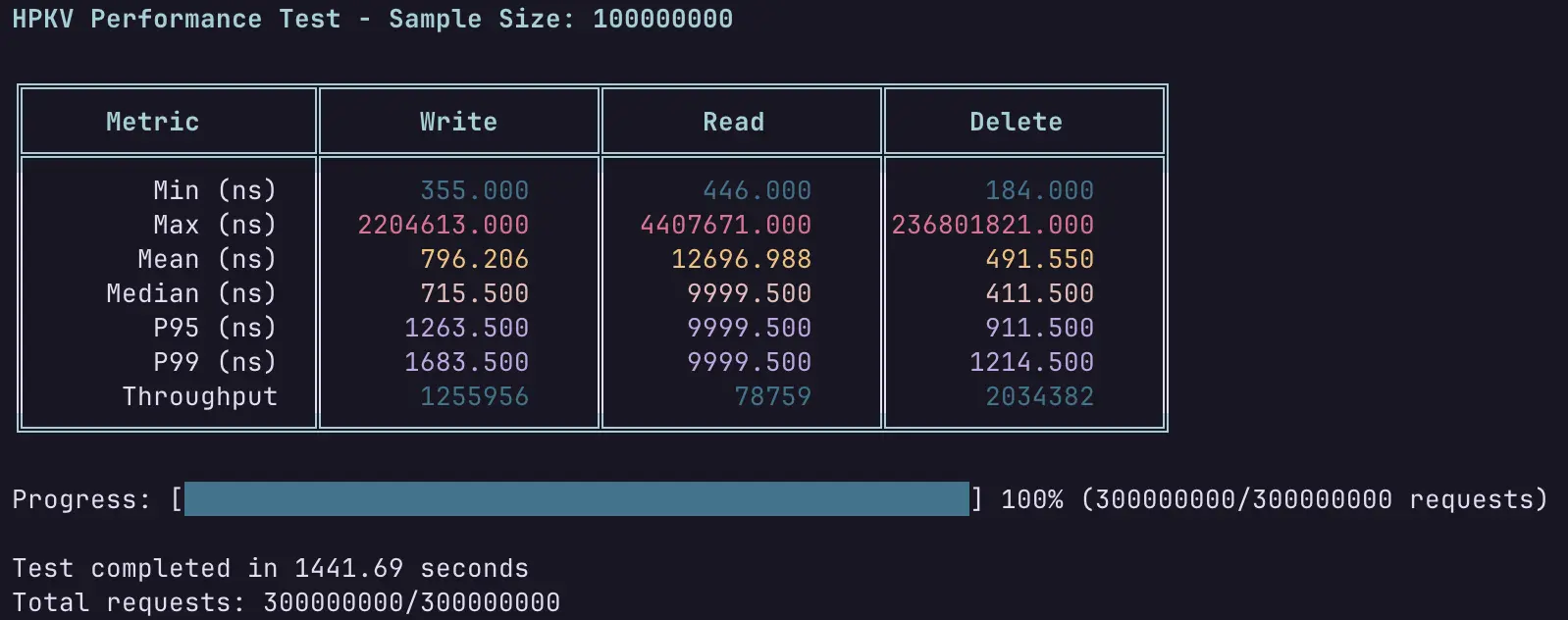
There are two important things to note here:
- The test is reading each key only once, so the latency number is the time it takes to read the value from the disk.
- Since the test is running in single-thread mode, the performance is effectively limited by the disk random read speed at QD1 4KB.
Here you can see the effect of the highly optimized custom file system that HPKV uses. 12 microseconds equals 83K IOPS or 320 MiB/s at QD1 4KB. This is very close to the theoretical max of the disk used in the test.
The HPKV's disk write speed is essentially limited by the disk random write speed at QD32 4KB (430K IOPS or 1.6 GiB/s) since the write buffer system automatically scales up and spins more workers to keep up with the write requests. During the above test, the write phase took 100 seconds to complete and the full flush to disk took an additional 130 seconds.
Now with local performance out of the way, let's dive into the over-the-network performance.
100M keys over the network (in-memory)
The following shows the benchmark result of 100M 100-byte values, 50 clients, pipelined 16 operations, sent over the network.
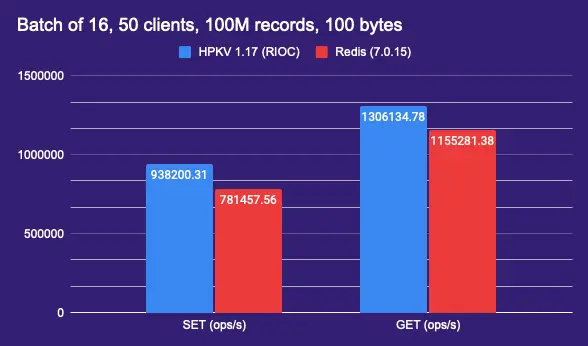
As you can see, during the GET operation, HPKV was essentially limited by the network speed.
It's worth noting that the Redis benchmark tool is used with the following parameters:
redis-benchmark -h xxx.xxx.xxx.xxx -n 100000000 -r 100000000 -t set,get -P 16 -q -c 50 -d 100
We're using the -r parameter to generate random keys in an effort to make the comparison fair to the RIOC benchmark tool that uses unique sequential keys; otherwise, redis-benchmark would only try to update the same key over and over again.
100M keys over the network (hybrid memory-disk)
The following shows the benchmark result of 100M 100-byte values, 50 clients, pipelined 16 operations, sent over the network. HPKV is running in hybrid memory-disk mode with hash buckets set to 2^28.
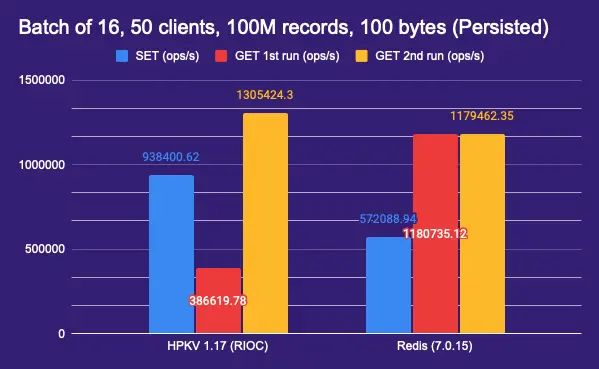
In this test you can see the effect of disk write speed on Redis write performance, but HPKV is still performing the same as in-memory mode. However, when it comes to reads, the first read is limited by the disk random read speed with the number of parallel reads done by the RIOC server, but the second read, where all keys are cached in memory, the performance is the same as in-memory mode.
Performance-to-cost ratio
At the beginning of this article, we mentioned that performance is not about the numbers, it's about the context. What HPKV offers is a superior performance-to-cost ratio.
On one side of the spectrum, HPKV can run in environments with very low memory and still provide excellent performance, only limited by disk speed, and on the other side of the spectrum, it can operate in memory-only mode and provide excellent nanosecond-range performance during local operation.
This will be the focus of the next article, showing how much you can save by using HPKV instead of Redis, without compromising performance.
Beta Testing HPKV Business Plan - For Free!
As you might know, we still haven't officially opened our Business plan, which offers RIOC yet; however, we're looking for a few early adopters and beta testers, free of charge.
If this is something that interests you, please contact me with your use case at [email protected] and I'll get back to you as soon as possible.